

AMD revealed during its results call that it will integrate Xilinx’s FPGA-powered AI inference engine into its CPU range, with the first devices expected in 2023. The news indicates that AMD is moving quickly to incorporate the benefits of its $54 billion Xilinx acquisition into its processor lineup, which isn’t entirely surprising given that the company’s recent patents show it is already well on its way to enabling multiple methods of connecting AI accelerators to its processors, including using sophisticated 3D chip stacking technology.
AMD’s desire to bundle its CPUs with in-built FPGAs isn’t entirely new; Intel tried something similar with the FPGA portfolio it acquired from Altera in late 2015 for $16.7 billion. However, even though Intel announced the combined CPU+FPGA chip in 2014 and even demonstrated a test chip, the silicon didn’t arrive until 2018, and then only in a limited experimental way that appears to have come to a halt.

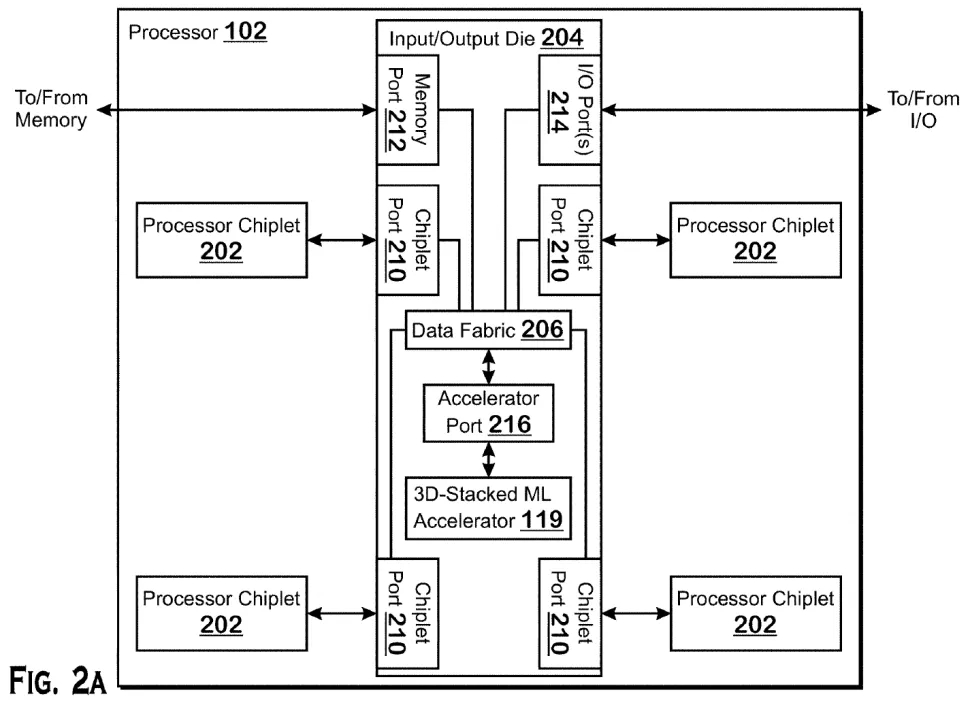
AMD hasn’t published any details on its FPGA-enabled devices yet, but the company’s strategy for connecting the Xilinx FPGA silicon to its chip will almost certainly be more complex. While Intel used normal PCIe lanes and its QPI interface to connect its FPGA chip to the CPU, AMD’s latest patents suggest that it is working on an accelerator port that might support a variety of packaging alternatives.
Three-dimensional stacking chip technology, similar to what it employs to join SRAM chiplets in its Milan-X processors, might be used to fuse an FPGA chiplet on top of the processors’ I/O die (IOD). This chip stacking strategy would improve performance, power, and memory throughput, but as we’ve seen with AMD’s existing 3D stacking chips, it can also cause heart issues that stymie performance if the chiplet is placed too close to the compute dies. AMD’s decision to put an accelerator on top of the I/O die makes logical because it would help alleviate heat issues, allowing AMD to squeeze more performance out of the CPU chiplets around it (CCDs).

Other choices are available from AMD. The corporation can handle stacked chiplets on top of other dies or simply arrange them in normal 2.5D implementations that use a discrete accelerator chiplet instead of a CPU chiplet by establishing an accelerator port (see above diagrams). AMD also has the option of including various types of accelerators, such as GPUs, ASICs, or DSPs. This opens up a slew of alternatives for AMD’s own exclusive future products, as well as the possibility of customers mixing and matching these chiplets into unique AMD semi-custom processors.
As the tsunami of personalization continues in the data centre, this type of foundational technology will undoubtedly come in handy, as proven by AMD’s recently announced 128-core EPYC Bergamo CPUs, which have a new type of ‘Zen 4c’ core that’s suited for cloud-native apps.
AMD is already addressing AI workloads with its data centre GPUs and CPUs, with the former often handling the compute-intensive process of training an AI model. AMD will largely employ the Xilinx FPGA AI engines for inference, which uses a pre-trained AI model to do a specific task.
Xilinx already utilises the AI engine in image recognition and “all types” of inference applications in embedded applications and edge devices, such as vehicles, according to Victor Peng, AMD’s president of its Adaptive and Embedded Computing branch, during the company’s earnings call. The design is scalable, according to Peng, making it a natural fit for the company’s CPUs.
Inference workloads require fewer processing resources and are significantly more common in data centre installations than training. As a result, inference workloads are widely deployed across large server farms, with Nvidia developing low-power inference GPUs such as the T4 and Intel relying on hardware-assisted AI acceleration in its Xeon CPUs to solve these workloads.
also read:
AMD confirms Phoenix and powerful Dragon Range APUs in its new Zen4 Roadmap
source






