

Based on its die size and transistor count, NVIDIA next-generation Hopper GH100 GPU will be a monster of a processor. It was rumoured a few weeks ago that NVIDIA Hopper GH100 flagship GPU would be built on a 5nm technology node with a die size of around 900mm2.
This would make it the largest GPU ever made, not only on the 5nm process node but in the history of the world. But that’s not all; a fresh report has surfaced on Chiphell Forums, claiming that the GPU would have over 140 billion transistors.
Current flagship data centre CPUs, such as AMD’s Aldebaran for Instinct MI200 series and NVIDIA’s Ampere GA100 for the A100 accelerators, have just 58.2 and 54.2 billion transistors, respectively. If the storey is genuine, the Hopper GH100 GPU will have about a 2.5x increase in overall transistor count.
The NVIDIA Ampere A100 has 65.6 million transistors per mm2, whereas the Aldebaran GPU (based on its estimated die size of 790mm2) should have 73.6 million transistors per mm2. If the GH100 is roughly 900mm2, the density should easily exceed 150 million transistors per mm2. On the 5nm process node, this is more than double the density increase.
However, keep in mind that these are all supposed values that will only apply to the monolithic GH100 Hopper GPU. According to reports, the MCM GPU will be a different entity and will be known as the GH102 GPU. Except for what study papers and rumours have taught us, we don’t know the exact details. Overall, both the monolithic and MCM versions of the NVIDIA Hopper GPU will offer a significant increase in transistor count and sophisticated 5nm packaging techniques.

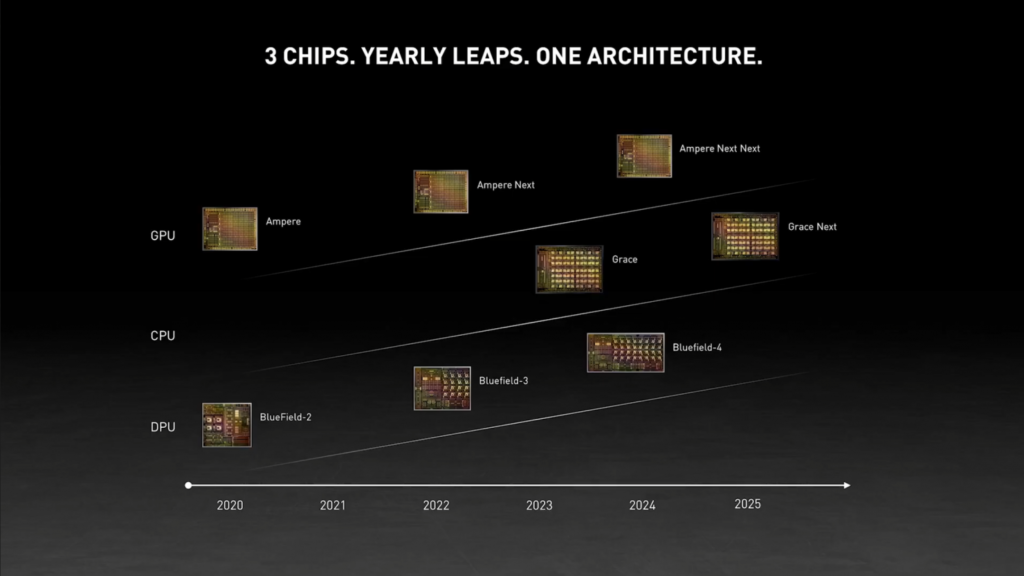
NVIDIA’s GH100 accelerator is said to be built on TSMC’s 5nm manufacturing node. Hopper is expected to include two next-generation GPU modules, totalling 288 SM units.
NVIDIA may also use more FP64, FP16, and Tensor cores in its Hopper GPU to further improve performance. And that will be required to compete with Intel’s Ponte Vecchio, which is likely to include 1:1 FP64.
The final configuration is likely to have 134 of the 144 SM units activated on each GPU module, implying that we’re looking at a single GH100 chip in action. However, without GPU Sparsity, NVIDIA is unlikely to achieve the same FP32 or FP64 Flops as MI200.

NVIDIA, on the other hand, may have a hidden weapon in the form of Hopper’s COPA-based GPU implementation. NVIDIA mentions two Domain-Specialized COPA-GPUs based on next-generation architecture, one for HPC and the other for DL. The HPC variant uses a relatively normal method, with an MCM GPU and HBM/MC+HBM (IO) chiplets, but the DL variation is where things start to get interesting. The DL version includes a large cache on a separate die that is coupled to the GPU modules.
There are several varieties with up to 960 / 1920 MB of LLC (Last-Level-Cache), up to 233 GB of HBM2e DRAM capacity, and up to 6.3 TB/s of bandwidth. These are all hypothetical, but given that NVIDIA has already mentioned them, we could see a Hopper variation with such an architecture at GTC 2022.
also read:
Microsoft outlines its plans for Windows Insider preview in 2022






