

The brand new model available is Llama 3.1 405B by Meta, which beats OpenAI’s ChatGPT-4o in a healthy set of benchmarks within the last few months This comparison looks at how Llama 3.1 405B and ChatGPT 4o perform as models with a very large context window, capable of processing up to be processed by the systems.

Llama 3.1 vs ChatGPT 4o
Performance on Reasoning Tasks
When evaluating the models on reasoning tasks, ChatGPT 4o performed well mainly at numerical comparisons and commonsense problems. In a nutshell, it solved number comparison and logical reasoning problems without fail. By comparison, Llama 3.1 405B was not as dependable and would often fail on even the most basic of reasoning questions.
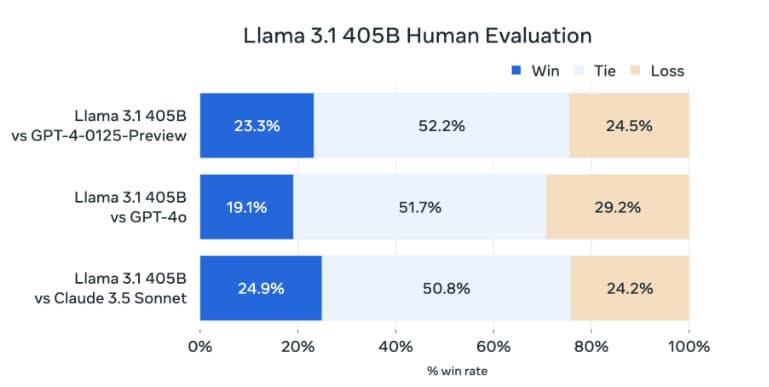
Handling Complex Queries
For more complex queries that require logical deductions and contextual understanding, both models performed fairly well. This being said, ChatGPT 4o was more fine-tuned and specific responses in the most up-to-date context subtleties. Llama 3.1 405B did work, however often weren’t as thorough or the accuracy of answers was not quite on par with ChatGPT 4o in some instances.
Coding and Programming Capabilities
The ChatGPT 4o model was especially useful when it came to coding and programming – not only generating full working code snippets but even for complicated assignments. Llama 3.1 405B lagged in the coding phase, and oftentimes failed to generate any functional or complete code. Instead, this emphasizes the freshers over ChatGPT 4o how easy is to write code and implement it.

Memory Recall and Contextual Understanding
Models were evaluated in memory recall and the ability to manage larger contexts. Llama 3.1 405B benefitted from a large context window; mastered long-text management and maintained much more of the input over longer conversations This feat also proved ChatGPT 4o was well able to understand the context in a strong manner.
Conclusion
While Llama 3.1 405B provides quite a number of abilities, mainly thanks to its large size for context which is very useful, ChatGPT-4o outperforms it overall in terms of reasoning understanding and coding support when dealing with nuanced inputs Overall, Llama 3.1 405B is still an important contribution to the AI ecosystem and has quite a bit of extra context that ChatGPT doesn’t have yet – if you really need your model to handle lots of fed-in context correctly, it might be useful.
FAQs
Which model is better for coding tasks?
ChatGPT 4o is superior in generating functional code compared to Llama 3.1 405B.
How do the models handle large amounts of context?
Both models handle large context well, but Llama 3.1 405B has an advantage with its larger context window.






